source : GCP qwiklabs
Cloud Dataproc API가 사용 설정되어 있는지 확인
- GCP에서 Dataproc 클러스터를 만들려면 Cloud Dataproc API 사용 설정 필요
API 사용 설정 확인
1. 탐색 메뉴 > API 및 서비스 > 라이브러리 클릭
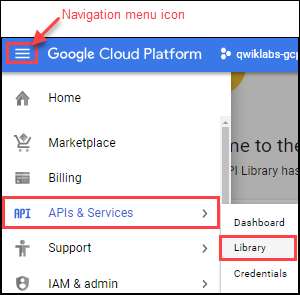
2. API 및 서비스 검색 대화 상자에 Cloud Dataproc을 입력 → 콘솔의 검색 결과에 Cloud Dataproc API가 표시됨
3. Cloud Dataproc API를 클릭하여 API 상태 표시
- API가 아직 사용 설정되지 않은 경우 사용 버튼 클릭

클러스터 만들기
- Cloud Platform Console에서 탐색 메뉴 > Dataproc > 클러스터 선택 > 클러스터 만들기 클릭
- 클러스터 필드 설정 (다른 모든 필드는 기본값 사용)
| 필드 | 값 |
| 이름 | example-cluster |
| 리전 | global |
| 영역 | us-central1-a |
※ 참고: 영역은 Google Compute 영역 전체에 인스턴스를 배포할 수 있는 다중 리전 네임스페이스로, us-east1 또는 europe-west1 같은 개별 리전을 지정하여, 사용자 지정 리전 내에서 Cloud Dataproc에 의해 사용되는 메타데이터 저장소 위치와 리소스(VM 인스턴스 및 Google Cloud Storage) 분리 가능

- 만들기를 클릭하여 클러스터 생성.
- 새 클러스터가 클러스터 목록 표시됨 (생성하는 데 몇 분이 소요될 수 있음)
- 클러스터를 사용할 준비가 될 때까지 클러스터 상태는 프로비저닝으로 표시되고, 그 이후 실행 중으로 변경
작업 제출(Submit job)
샘플 Spark 작업을 실행
- 왼쪽 창에서 작업을 클릭하여 Dataproc의 작업 보기로 전환한 다음 작업 제출 클릭

- 필드 설정하여 작업 업데이트 (다른 모든 필드는 기본값 사용)
| 필드 | 값 |
| 클러스터 | example-cluster |
| 작업 유형 | Spark |
| 기본 클래스 또는 jar | org.apache.spark.examples.SparkPi |
| 인수 | 1000(작업 수를 설정합니다.) |
| Jar 파일 | file:///usr/lib/spark/examples/jars/spark-examples.jar |

- 제출 클릭
Pi 계산 방법
- Spark 작업은 Monte Carlo 방법을 사용하여 Pi 값을 추정
- 이 방법은 정사각형으로 둘러싸인 원을 모델링하는 좌표 평면에 x,y 점을 생성
- 입력 인수(1000)는 생성할 x,y 쌍의 수를 결정 (더 많은 쌍이 생성되면 더 정확한 추정 가능)
- 이 추정에서는 Cloud Dataproc 워커 노드를 활용하여 계산을 병렬 처리
※ 참고 : Monte Carlo 방법을 사용하여 Pi 추정 및 GitHub의 JavaSparkPi.java
- 현재 작업이 작업 목록에 나타남 (이 목록에는 프로젝트의 작업이 클러스터, 유형 및 현재 상태와 함께 표시)
- 작업 상태는 실행 중으로 표시된 후 완료되면 성공으로 표시됨

작업 결과 보기
- 작업 목록에서 작업 ID를 클릭합니다.
- 줄바꿈을 선택하거나, 오른쪽으로 스크롤하여 Pi의 계산된 값 확인
출력 예시 (줄바꿈 선택한 경우)

클러스터 업데이트
1. 왼쪽 탐색창에서 클러스터를 선택하여 Dataproc 클러스터 보기로 돌아감
2. 클러스터 목록에서 example-cluster를 클릭 (기본적으로 페이지에는 클러스터의 CPU 사용 개요 표시됨)
3. 구성을 클릭하여 클러스터의 현재 설정 표시
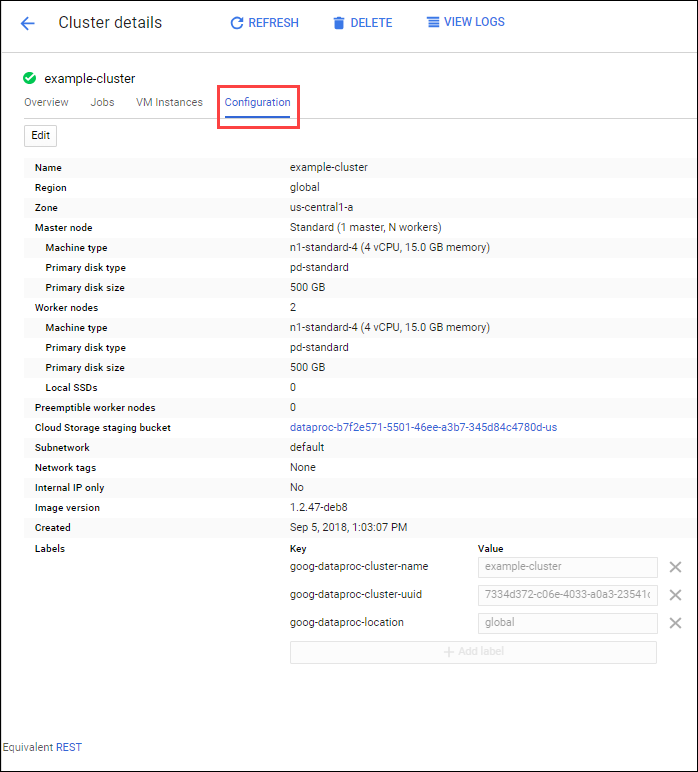
4. 편집 클릭 (워커 노드 수 편집)
5. 워커 노드 필드에 4를 입력
6. 저장 클릭

7. 클러스터가 완료 → 클러스터의 VM 인스턴스 수 확인.

- 업데이트된 클러스터 작업을 다시 실행하려면, 왼쪽 창에서 작업을 클릭한 다음 작업 제출 클릭
- 작업 제출 섹션에서 설정한 것과 동일하게 필드 설정
| 필드 | 값 |
| 클러스터 | example-cluster |
| 작업 유형 | Spark |
| 기본 클래스 또는 jar | org.apache.spark.examples.SparkPi |
| 인수 | 1000(작업 수를 설정합니다.) |
| Jar 파일 | file:///usr/lib/spark/examples/jars/spark-examples.jar |
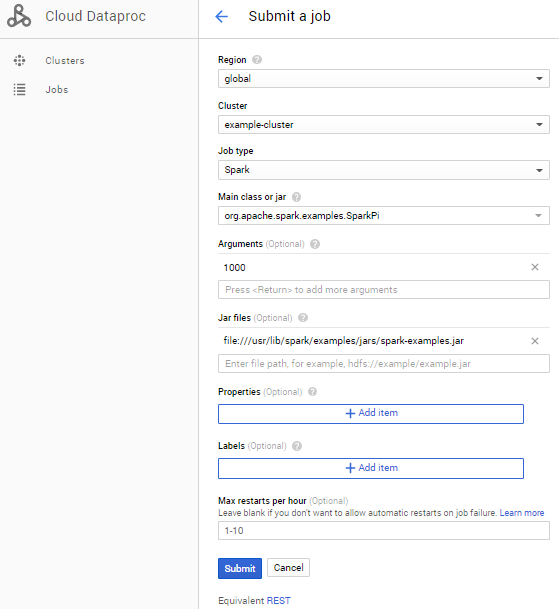
- 제출 클릭
'Biusiness Insight > Computer Science' 카테고리의 다른 글
| 메타버스 (Metaverse) 기본 개념 (0) | 2021.06.12 |
|---|---|
| [AWS] 아마존 S3 예제 (Amazon S3, Simple Storage Service) (0) | 2021.05.20 |
| [구글 클라우드] Dataproc 클러스터 만들기 (명령 프롬프트) (0) | 2020.04.01 |
| [구글 클라우드 플랫폼] 네트워크 및 HTTP 부하 분산 설정하기 (0) | 2020.03.29 |
| [구글 클라우드 플랫폼] Kubernetes Engine 클러스터 설정 (0) | 2020.03.28 |



