반응형
단원별 심화 연습 문제¶
In [1]:
!pip install seaborn==0.13.0
Defaulting to user installation because normal site-packages is not writeable
Collecting seaborn==0.13.0
Downloading seaborn-0.13.0-py3-none-any.whl (294 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 294.6/294.6 kB 6.6 MB/s eta 0:00:00a 0:00:01
Requirement already satisfied: numpy!=1.24.0,>=1.20 in ./.local/lib/python3.9/site-packages (from seaborn==0.13.0) (1.23.3)
Requirement already satisfied: pandas>=1.2 in ./.local/lib/python3.9/site-packages (from seaborn==0.13.0) (1.4.2)
Requirement already satisfied: matplotlib!=3.6.1,>=3.3 in ./.local/lib/python3.9/site-packages (from seaborn==0.13.0) (3.6.0)
Requirement already satisfied: packaging>=20.0 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (21.3)
Requirement already satisfied: kiwisolver>=1.0.1 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (1.4.4)
Requirement already satisfied: contourpy>=1.0.1 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (1.0.6)
Requirement already satisfied: fonttools>=4.22.0 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (4.38.0)
Requirement already satisfied: cycler>=0.10 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (0.11.0)
Requirement already satisfied: python-dateutil>=2.7 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (2.8.2)
Requirement already satisfied: pillow>=6.2.0 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (9.3.0)
Requirement already satisfied: pyparsing>=2.2.1 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (3.0.9)
Requirement already satisfied: pytz>=2020.1 in ./.local/lib/python3.9/site-packages (from pandas>=1.2->seaborn==0.13.0) (2022.5)
Requirement already satisfied: six>=1.5 in ./.local/lib/python3.9/site-packages (from python-dateutil>=2.7->matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (1.16.0)
Installing collected packages: seaborn
Attempting uninstall: seaborn
Found existing installation: seaborn 0.12.0
Uninstalling seaborn-0.12.0:
Successfully uninstalled seaborn-0.12.0
Successfully installed seaborn-0.13.0
[notice] A new release of pip available: 22.2.2 -> 24.1.1
[notice] To update, run: pip install --upgrade pip
In [2]:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import seaborn as sns
import glob
from IPython.display import Image
# set floating point formatting
pd.options.display.float_format = '{:,.6f}'.format
/mnt/elice/dataset/StudentsPerformance.csv파일을 읽어서 DataFrame 형식으로 출력합니다. (상위 5개 행을 출력 합니다.)
In [3]:
# 데이터셋 로드
import pandas as pd
students = pd.read_csv('/mnt/elice/dataset/StudentsPerformance.csv')
students.head()
Out[3]:
| gender | race/ethnicity | parental level of education | lunch | test preparation course | math score | reading score | writing score | |
|---|---|---|---|---|---|---|---|---|
| 0 | female | group B | bachelor's degree | standard | none | 72 | 72 | 74 |
| 1 | female | group C | some college | standard | completed | 69 | 90 | 88 |
| 2 | female | group B | master's degree | standard | none | 90 | 95 | 93 |
| 3 | male | group A | associate's degree | free/reduced | none | 47 | 57 | 44 |
| 4 | male | group C | some college | standard | none | 76 | 78 | 75 |
다음의 요구사항에 맞는 데이터프레임을 출력하세요
students데이터프레임의race/ethnicity가group B인 그룹을 필터합니다.gender가male인 대상을 필터합니다.math score,reading score,writing score에 대한평균(mean)과표준편차(std)를 출력합니다.
In [5]:
# 코드를 입력해 주세요
group_b_students = students[students['race/ethnicity'] == 'group B']
group_b_male_students = group_b_students[group_b_students['gender'] == 'male']
result = group_b_male_students[['math score', 'reading score', 'writing score']].agg(['mean', 'std'])
result
Out[5]:
| math score | reading score | writing score | |
|---|---|---|---|
| mean | 65.930233 | 62.848837 | 60.220930 |
| std | 14.156928 | 14.695752 | 14.854907 |
[출력 결과]
| math score | reading score | writing score | |
|---|---|---|---|
| mean | 65.930233 | 62.848837 | 60.220930 |
| std | 14.156928 | 14.695752 | 14.854907 |
다음의 요구사항에 맞는 데이터프레임을 출력하세요
students데이터프레임에서gender가male인 대상을 필터합니다.lunch가standard대상을 필터합니다.reading score가 80 이상인 데이터를 필터합니다.math score,reading score,writing score에 대한 요약통계(describe)를 출력합니다.
In [6]:
# 코드를 입력해 주세요
male_students = students[students['gender'] == 'male']
standard_lunch_male_students = male_students[male_students['lunch'] == 'standard']
filtered_students = standard_lunch_male_students[standard_lunch_male_students['reading score'] >= 80]
result = filtered_students[['math score', 'reading score', 'writing score']].describe()
result
Out[6]:
| math score | reading score | writing score | |
|---|---|---|---|
| count | 68.000000 | 68.000000 | 68.000000 |
| mean | 87.897059 | 85.470588 | 82.955882 |
| std | 6.388281 | 4.872924 | 6.391304 |
| min | 75.000000 | 80.000000 | 71.000000 |
| 25% | 83.000000 | 82.000000 | 78.000000 |
| 50% | 87.000000 | 84.000000 | 82.000000 |
| 75% | 92.250000 | 87.000000 | 86.250000 |
| max | 100.000000 | 100.000000 | 100.000000 |
[출력 결과]
| math score | reading score | writing score | |
|---|---|---|---|
| count | 68.000000 | 68.000000 | 68.000000 |
| mean | 87.897059 | 85.470588 | 82.955882 |
| std | 6.388281 | 4.872924 | 6.391304 |
| min | 75.000000 | 80.000000 | 71.000000 |
| 25% | 83.000000 | 82.000000 | 78.000000 |
| 50% | 87.000000 | 84.000000 | 82.000000 |
| 75% | 92.250000 | 87.000000 | 86.250000 |
| max | 100.000000 | 100.000000 | 100.000000 |
위의 표를 참고하여 math score, reading score, writing score의 IQR을 산정합니다.
- IQR(Inter Quantile Range) = ((3rd Quantile, 75%) - (1st Quantile, 25%)) * 1.5
- IQR Bottom = (1st Quantile, 25%) - IQR
- IQR Top: (3rd Quantile, 75%) + IQR
In [7]:
Image(url='https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcAqc6V%2FbtqyQLiddUd%2FiXQVu1nYTo2rx3Q8xZBqy0%2Fimg.png')
Out[7]:
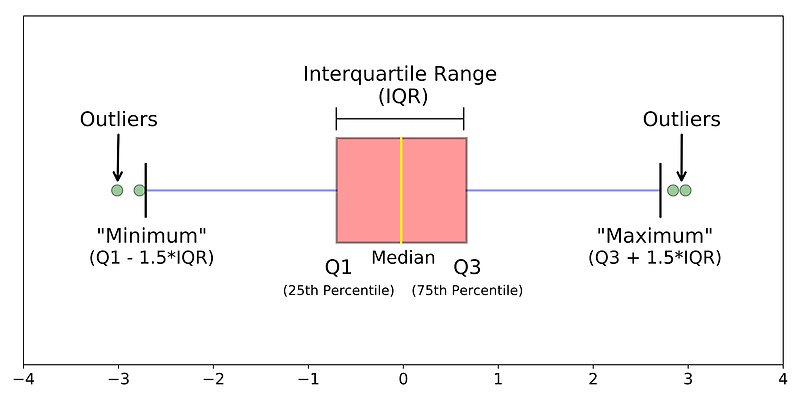
위에 명시된 공식을 참고하여 IQR Bottom을 산출해 주세요
In [19]:
# 코드를 입력해 주세요
#IQR(Inter Quantile Range) = ((3rd Quantile, 75%) - (1st Quantile, 25%)) * 1.5
#IQR Bottom = (1st Quantile, 25%) - IQR
#IQR Top: (3rd Quantile, 75%) + IQR
IQR = (result.quantile(0.75) - result.quantile(0.25))*1.5
IQR_bottom = result.quantile(0.25) - IQR
IQR_bottom
Out[19]:
math score 49.647059 reading score 63.720588 writing score 49.955882 dtype: float64
[출력 결과]
math score 69.125 reading score 74.500 writing score 65.625 dtype: float64
위에 명시된 공식을 참고하여 IQR Top을 산출해 주세요
In [20]:
# 코드를 입력해 주세요
IQR_top = result.quantile(0.75) + IQR
IQR_top
Out[20]:
math score 112.588235 reading score 99.132353 writing score 104.073529 dtype: float64
[출력 결과]
math score 106.125 reading score 94.500 writing score 98.625 dtype: float64
제출¶
제출을 위해 새로 로드된 /mnt/elice/dataset/StudentsPerformance.csv 데이터셋에서 다음 요구사항에 맞는 데이터프레임을 result_df에 저장하세요.
students데이터프레임에서gender가male인 대상을 필터합니다.lunch가standard대상을 필터합니다.reading score가 80 이상인 데이터를 필터합니다.math score,reading score,writing score에 대한 요약통계(describe)
In [24]:
students = pd.read_csv('/mnt/elice/dataset/StudentsPerformance.csv')
cond = students['gender'] == 'male'
cond2 = students['lunch'] == 'standard'
cond3 = students['reading score']>=80
filtered_students = students.loc[cond & cond2 & cond3, ['math score', 'reading score', 'writing score']]
result_df = filtered_students.describe()
result_df
Out[24]:
| math score | reading score | writing score | |
|---|---|---|---|
| count | 68.000000 | 68.000000 | 68.000000 |
| mean | 87.897059 | 85.470588 | 82.955882 |
| std | 6.388281 | 4.872924 | 6.391304 |
| min | 75.000000 | 80.000000 | 71.000000 |
| 25% | 83.000000 | 82.000000 | 78.000000 |
| 50% | 87.000000 | 84.000000 | 82.000000 |
| 75% | 92.250000 | 87.000000 | 86.250000 |
| max | 100.000000 | 100.000000 | 100.000000 |
반응형
'Biusiness Insight > Data Science' 카테고리의 다른 글
| [Python] Pandas 복제, 결측치 실습 (0) | 2024.06.30 |
|---|---|
| [Python] Pandas 복제, 결측치 (0) | 2024.06.30 |
| [Python] Pandas 통계 (0) | 2024.06.30 |
| [Python] Pandas 실습 (0) | 2024.06.30 |
| [Python] Pandas 조회, 정렬, 조건 필터 (타이타닉 승객 데이터) (0) | 2024.06.30 |