soruce : GCP qwiklabs
프로젝트에 Cloud Storage 버킷 만들기
1. Cloud Platform Console에서 탐색 메뉴 > 저장소 > 브라우저 선택
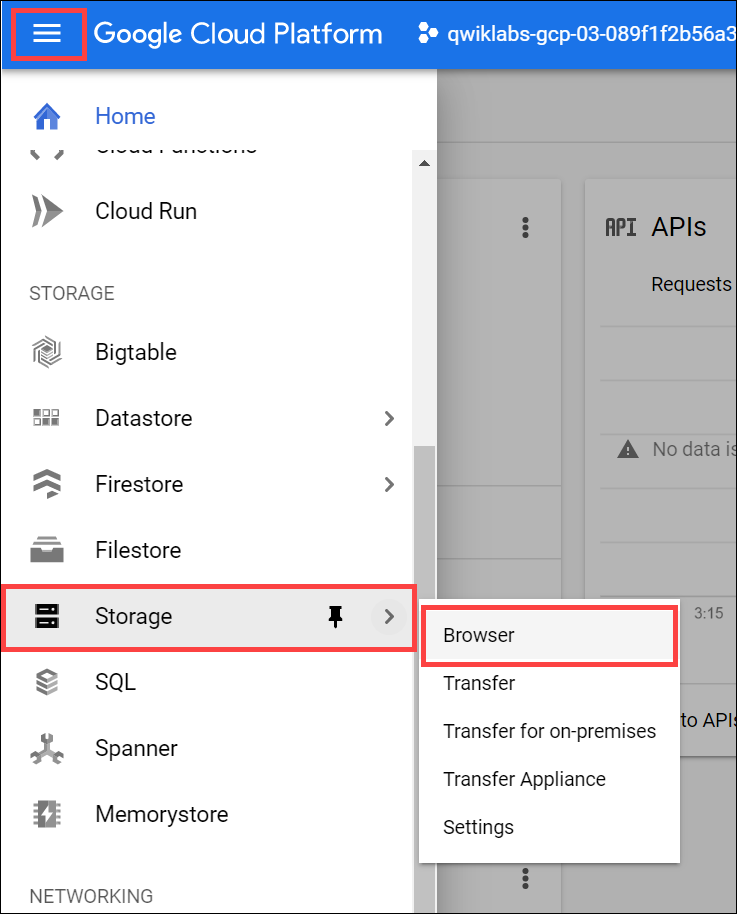
2. 버킷 만들기를 클릭합니다.
3. 버킷 만들기 대화상자에서 버킷 이름 지정 (참고: 버킷 이름 요구사항)
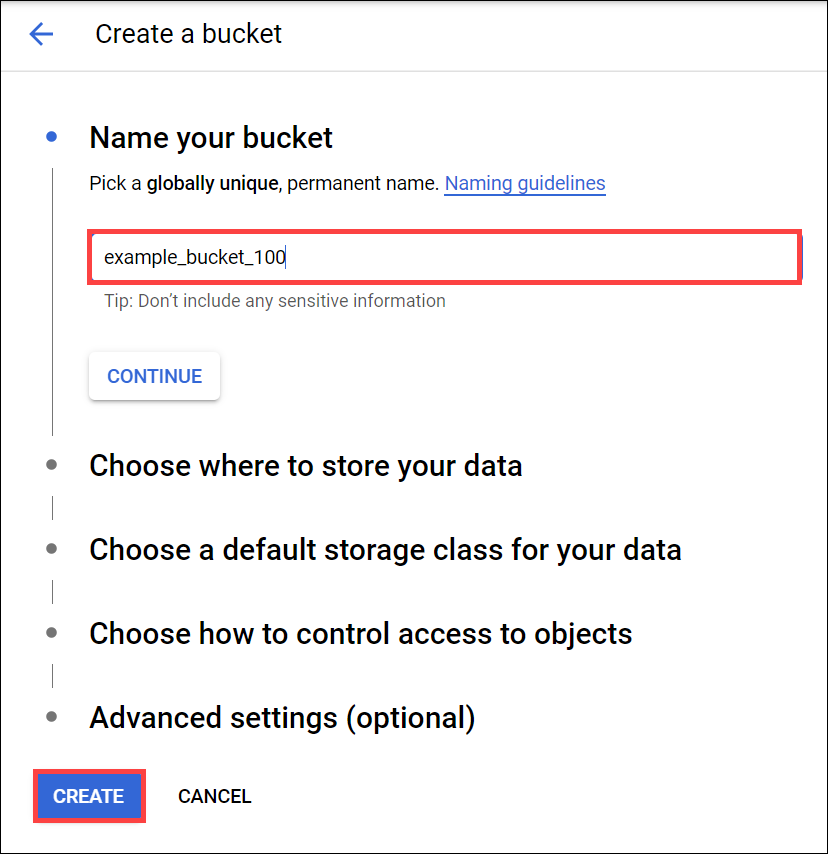
4. 만들기(Create) 클릭
Cloud Dataprep 초기화
- 탐색 메뉴 > Dataprep 선택
- Google Dataprep 서비스 약관에 동의하는 체크박스를 선택하고 동의 클릭
- 체크박스를 선택하여 Trifacta와의 계정 정보 공유를 승인한 다음 동의 및 계속하기 클릭
- 허용을 클릭하여 Trifacta가 프로젝트 데이터에 액세스하도록 허용
- Trifacta에서 제공하는 Cloud Dataprep에 로그인할 때 사용할 GCP 사용자 이름을 클릭. GCP 사용자 이름은 연결 세부정보 패널의 사용자 이름임.
- 허용을 클릭하여 GCP 실습 계정에 대한 액세스 권한을 Cloud Dataprep에 부여
- 체크박스를 선택하고 동의를 클릭하여 Trifacta 서비스 약관에 동의
- '처음 설정' 화면에서 계속을 클릭하여 기본 저장소 위치 생성
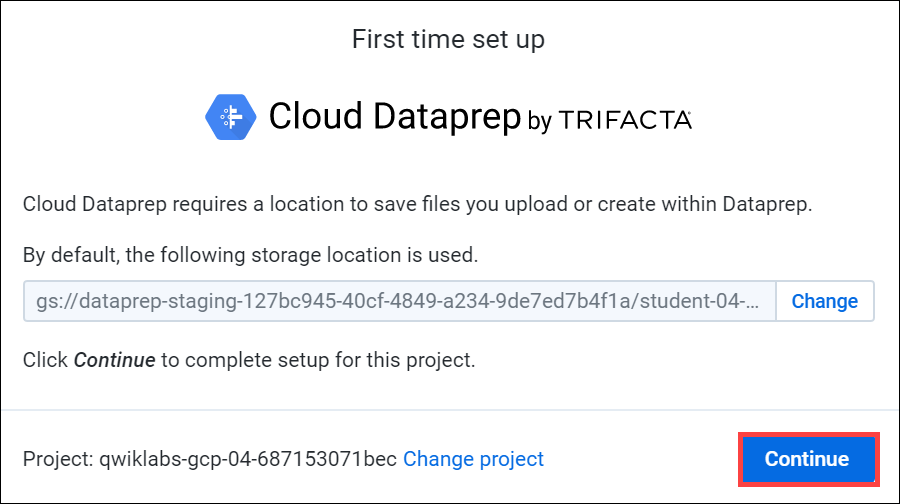
새 브라우저 탭에서 Dataprep 오픈됨. 시작 페이지의 오른쪽 상단에서 Hide tour 를 클릭
플로우 만들기
Cloud Dataprep은 flow 작업공간을 사용하여 데이터세트에 액세스하고 조작
1. 오른쪽 상단에 있는 플로우 만들기(Create Flow) 클릭

2. 흐름의 이름과 설명 입력 (예: 미국 연방 선거 관리 위원회 2016)
- 이름 : "FEC-2016" / 설명 : "미국 연방 선거 관리 위원회 2016"

3. Create(만들기)를 클릭합니다.
- FEC-2016 흐름 페이지가 열림
- "What's a flow?" 슬라이드를 스크롤하여 다음에 수행할 작업에 대한 개요를 보거나, Don't show me any helpers(도우미 표시 안 함)을 클릭하여 건너뜀
데이터세트 가져오기
이 섹션에서는 데이터를 가져와서 FEC-2016 흐름에 추가
1. Import & Add Datasets(데이터세트 가져오기 및 추가)를 클릭

2. 왼쪽 메뉴 창에서 GCS 선택 > Google Cloud Storage에서 데이터세트를 가져온 다음 연필을 클릭하여 파일 경로수정

3. Choose a file or folder(파일 또는 폴더 선택) 텍스트 상자에 gs://spls/gsp105를 입력한 다음 Go() 을 클릭
- Go(이동) 및 Cancel(취소) 버튼이 보이지 않으면 브라우저 창을 넓힙니다.
4. cn-2016.txt 옆의 + 아이콘을 클릭하여 오른쪽 창에 표시되는 데이터세트 만듬
- 데이터세트의 제목을 클릭하고 이름을 "Candidate Master 2016"으로 변경
5. 같은 방식으로 itcont-2016.txt 데이터세트를 추가하고 이름을 "Campaign Contributions 2016"으로 변경
6. 오른쪽 창에 두 데이터세트가 나열되면 Import & Add to Flow(가져오기 및 플로우에 추가)를 클릭
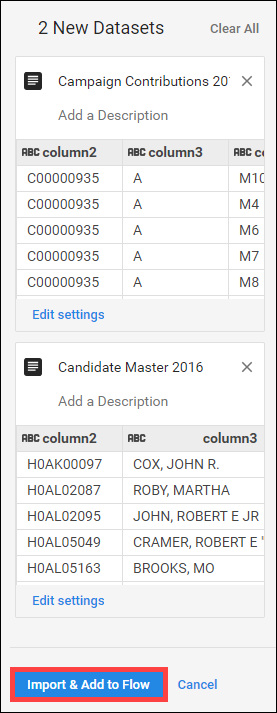
두 데이터세트가 모두 플로우로 표시됨

Candidate 파일 준비
1. 기본적으로 Candidate Master 2016 데이터세트가 선택됨. 오른쪽 창에서 Add New Recipe(새 레시피 추가) 클릭
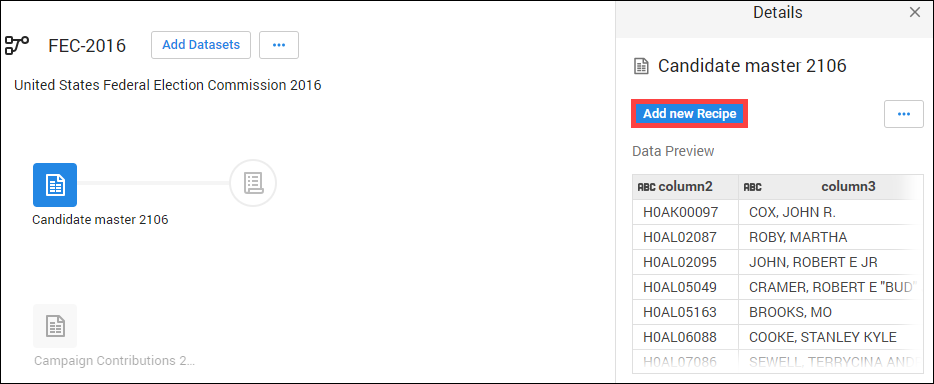
2. Edit Recipe(레시피 수정) 클릭

Candidate Master 2016-2 변환 페이지가 그리드 뷰로 열림
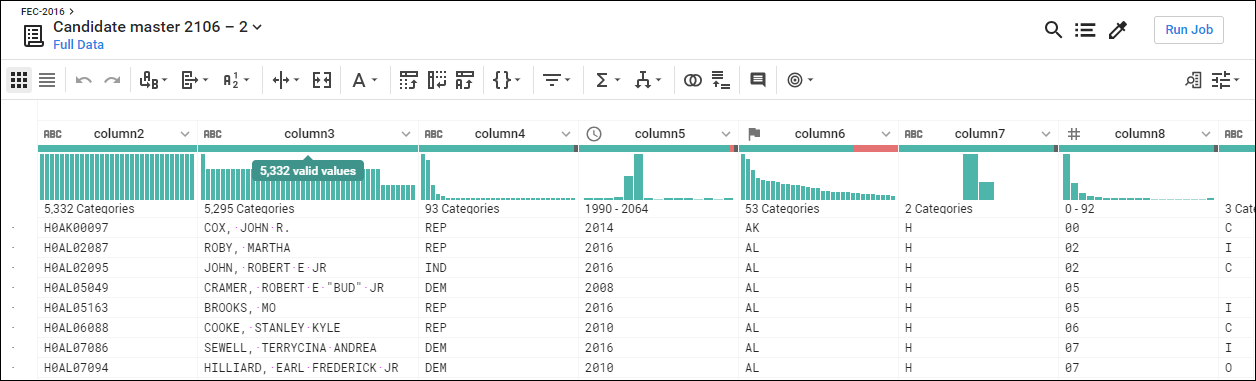
- 변환 페이지에서는 변환 레시피를 빌드하고 이를 샘플에 적용한 결과를 볼 수 있음
- 각 열 머리글에는 데이터 유형을 지정한 이름과 값 확인 가능. 플래그 아이콘을 클릭하면 데이터 유형이 표시됨.

- 플래그 옵션을 클릭하면 오른쪽에 Details(세부 사항) 패널이 활성화됨

- 세부 정보 패널의 오른쪽 위에있는 X 를 클릭하여 세부 정보 패널을 닫음
다음, 격자보기에서 데이터를 탐색하고 레시피에 변환 단계를 적용
1. Column5는 1990-2064년의 데이터를 제공
- 스프레드시트에서와 같이 column5를 넓히면 각 연도가 분리됨
- 2016년을 나타내는 가장 큰 빈을 클릭하여 선택

- 그러면 이 값을 선택하는 단계가 만들어짐
2. 오른쪽의 Suggestions(추천) 패널에 있는 Keep rows(행 유지) 섹션에서 Add(추가) 를 클릭하여 이 단계를 레시피에 추가

- 오른쪽의 레시피 패널에 다음 단계가 있음
- Keep rows where(date(2016, 1, 1) <= column5) && (column5 < date(2018, 1, 1))
3. Column6(State)을 마우스로 가리킨 다음 헤더에서 일치하지 않는 부분(빨간색)을 클릭하여 일치하지 않는 행을 선택

- 아래로 스크롤하여 일치하지 않는 값을 찾으면 해당되는 레코드 대부분에 column7의 값이 'P', column6의 값이 'US'로 되어 있음을 확인 가능.
- 이 불일치는 'State' 열(플래그 아이콘으로 표시)로 표시되어 있는 column6에 State가 아닌 값(예: 'US')이 포함되어 있기 때문에 발생
4. 불일치를 수정하려면 제안 패널 맨위에서 X 를 클릭하여 변환을 취소한 다음, Column6에서 플래그 아이콘을 클릭하고 "String"열로 변경

- 더 이상 불일치 항목이 없으먄 열이 녹색으로 바뀜
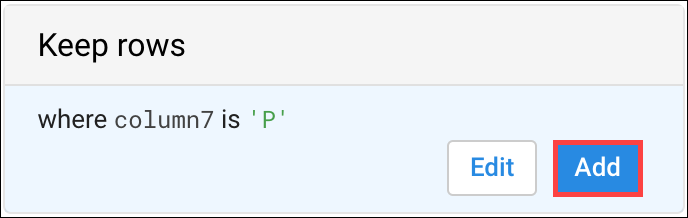
5. 대선 후보자 필터링 (column7에 값 'P' 레코드)
- column7의 히스토그램에서 두 개의 빈을 가리키면 'H'와 'P' 값을 갖는 빈 확인 가능
- 'P' 빈을 클릭

6. 오른쪽 제안 패널에서 Add(추가) 를 클릭하여 레시피 단계 승인
Contributions 파일 조인하기
- 조인 페이지에서 두 데이터세트의 공통 정보에 따라 현재 데이터세트를 다른 데이터세트나 레시피에 추가 가능
- Contributions 파일을 Candidates 파일에 조인하기 전에 Contributions 파일을 정리해야 함
1. 그리드 뷰 페이지 상단에서 FEC-2016(데이터세트 선택기)을 클릭

2. 회색으로 표시된 Campaign Contributions를 클릭하여 선택
3. 오른쪽 창에서 Add New Recipe(새 레시피 추가) 를 클릭한 다음 Edit Recipe(레시피 수정) 클릭
4. 페이지 오른쪽 상단의 recipe(레시피) 아이콘을 클릭한 다음 New step 추가 클릭

- 데이터세트에서 불필요한 구분 기호를 제거
5. 검색창에 다음과 같은 Wrangle 언어 명령어 삽입
replacepatterns col: * with: '' on: `{start}"|"{end}` global: true
변환 빌더가 Wrangle 명령어를 파싱하여 찾기 및 바꾸기 변환 필드를 채움
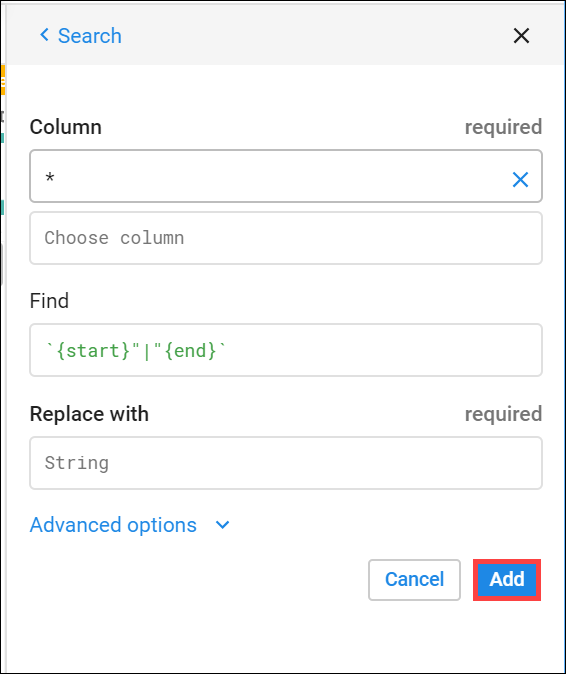
6. Add(추가) 를 클릭하여 해당 변환을 레시피에 추가
7. 레시피에 또 다른 New step 를 추가한 다음 New step(새 단계)를 클릭하고 검색창에 'Join'을 입력

8. 조인 페이지를 열려면 Join datasets(데이터세트 조인하기) 클릭
9. "Candidate Master 2016-2"를 클릭하여 Campaign Contributions-2에 조인한 다음 오른쪽 하단에 있는 Accept(수락) 클릭

10. 조인 키 섹션에 마우스를 올려 놓고 연필(수정 아이콘) 클릭

- Dataprep은 공통 키를 유추하는데 다양한 공통 값을 조인 키로 추천
11. 키 추가 패널의 추천 조인 키 섹션에서 'column2 = column11' 클릭

12. Save and Continue(저장 후 계속) 을 클릭 - 검토할 수 있도록 열 2, 11이 열림
13. Next(다음) 을 클릭하고 '열' 레이블의 왼쪽에 있는 체크박스를 선택하여 두 데이터세트의 모든 열을 조인된 데이터세트에 추가
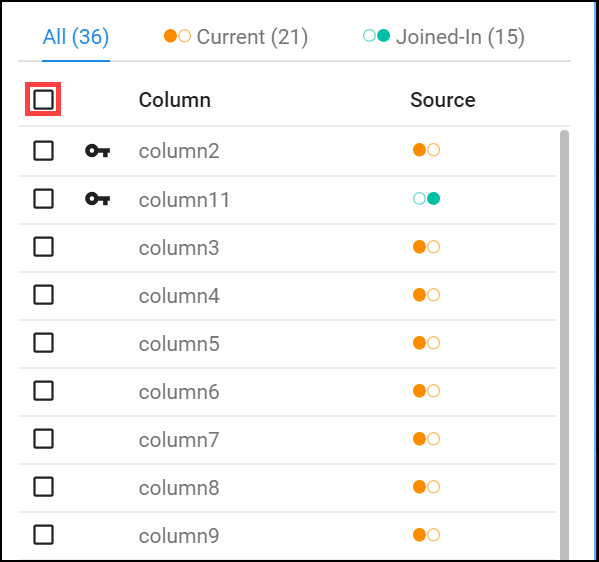
14. Review(검토) 를 클릭 한 다음 Add to Recipe(레시피에 추가) 를 클릭하여 격자보기로 돌아갑니다.
데이터 요약
- 열 16에 입력된 선거 자금 데이터의 총계, 평균, 항목 수를 계산하고 열 2, 24, 8의 ID, 이름, 소속 정당 데이터로 후보자를 그룹화해서 요약 생성
1. New step(새 단계)를 클릭하고 Transformation(변환) 검색창에 다음 수식을 입력하여 집계된 데이터를 미리봅니다.
pivot
value:sum(column16),average(column16),countif(column16 > 0)
group: column2,column24,column8
- 조인되어 집계된 데이터의 초기 샘플이 표시됨
- 이 샘플은 미국의 주요 대선 후보자들에 대한 요약표와 2016년 선거 자금 통계를 나타냄
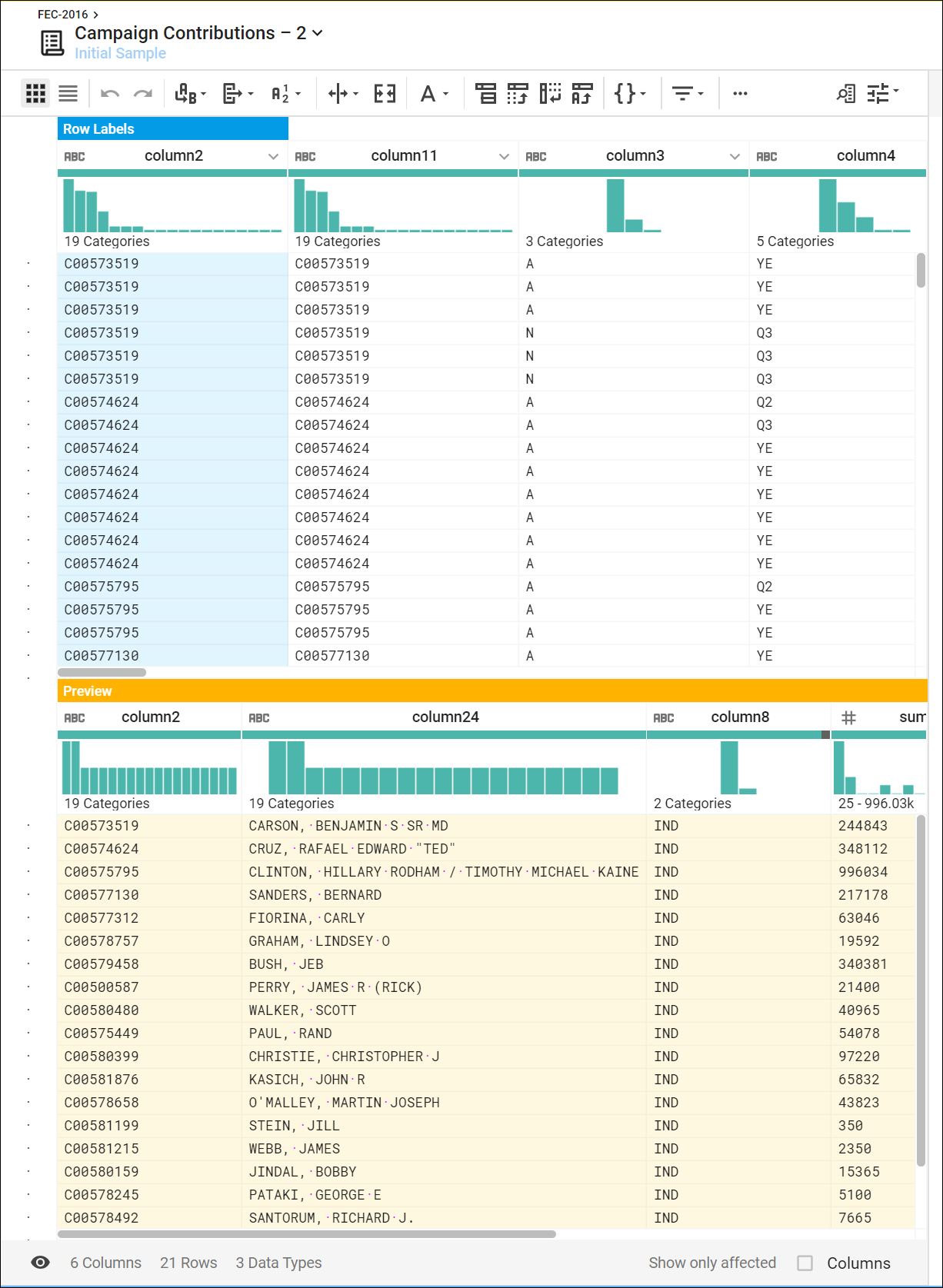
2. Add(추가) 를 클릭하여 미국의 주요 대선 후보자들에 대한 요약표와 2016년 선거 자금 통계 확인

열 이름 변경
- 열 이름을 변경하면 데이터를 더 쉽게 해석 가능
- New step(새 단계) 클릭 > 이름 바꾸기 및 라운딩 단계를 레시피에 개별적으로 추가 > 아래 내용 입력 > Add(추가) 클릭
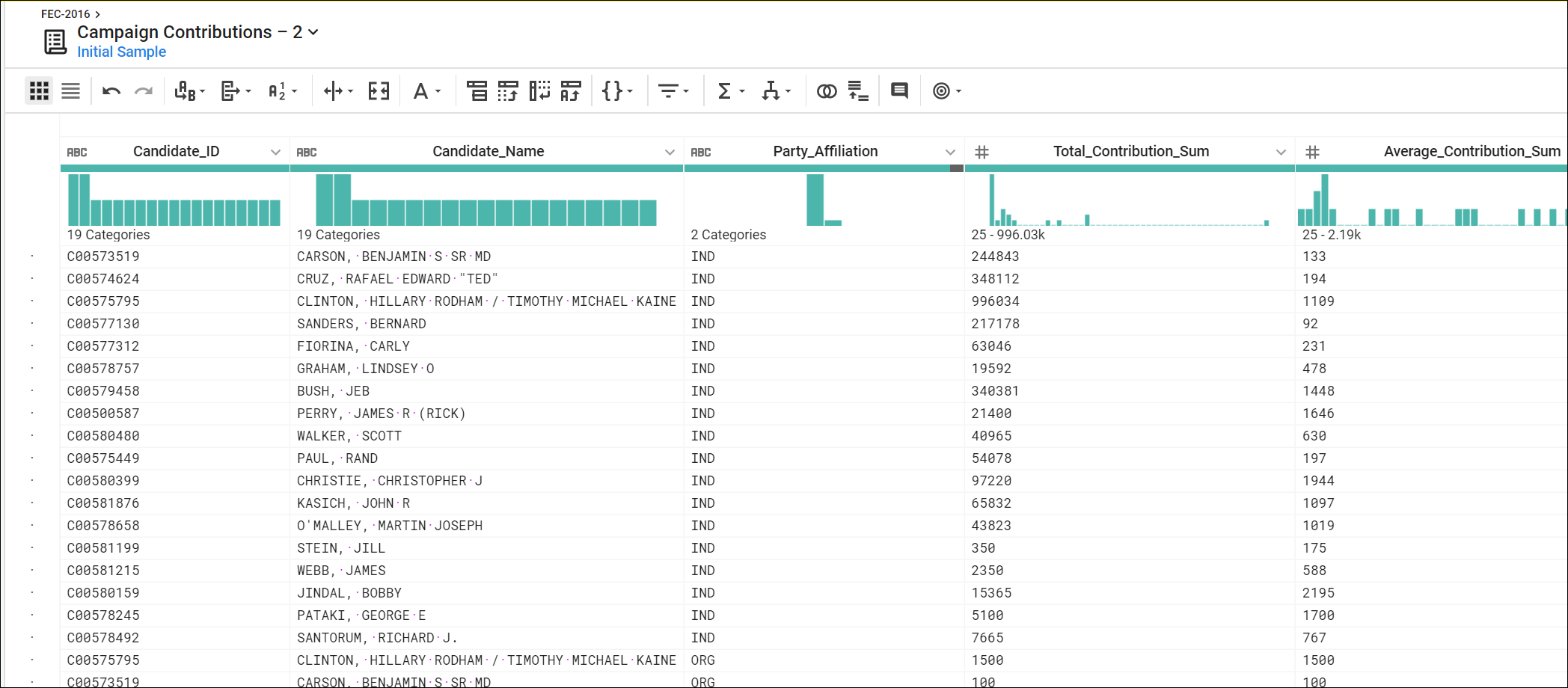
rename type: manual mapping:
[column24,'Candidate_Name'],
[column2,'Candidate_ID'],
[column8,'Party_Affiliation'],
[sum_column16,'Total_Contribution_Sum'],
[average_column16,'Average_Contribution_Sum'],
[countif,'Number_of_Contributions']
- 선거 자금 평균값을 라운딩하는 마지막 New step(새 단계) 추가
set col: Average_Contribution_Sum value:
round(Average_Contribution_Sum)
- Add(추가) 클릭
출력 화면 :
'Biusiness Insight > Gen AI · Data Analytics' 카테고리의 다른 글
| [구글 클라우드] 영상 분석 예제 (Video Intelligence) (0) | 2020.04.04 |
|---|---|
| [구글 클라우드] 음성 처리 API 활용 예제 (Speech API) (0) | 2020.04.03 |
| [구글 클라우드] 자연어 처리 API 사용 예제 (Natural Language API) (0) | 2020.04.02 |
| [구글 클라우드] Dataflow 템플릿 활용 스트리밍 파이프라인 만들기 (1) | 2020.03.31 |
| 구글 클라우드 플랫폼(GCP)을 활용한 데이터 분석 Essential 참고사항 (0) | 2020.03.09 |


