Pandas 란?
- Python을 이용한 데이터 분석의 필수 라이브러리로, 데이터 처리에 유용
- Pandas 활용 참고 링크
- 주로 3가지 데이터 구조 활용 : 시리즈(Series), 데이터프레임(DataFrame), 패널(Panel)
Pandas DataFrame 생성 (데이터프레임 만들기)
- 데이터프레임(DataFrame) 이란 : 2차원 행렬로 행방향 인덱스(index), 열방향 컬럼(column) 자료구조
- pd.DataFrame
from pandas import DataFrame, Series
def create_dataframe():
countries = ['Russian Fed.', 'Norway', 'Canada', 'United States',
'Netherlands', 'Germany', 'Switzerland', 'Belarus',
'Austria', 'France', 'Poland', 'China', 'Korea',
'Sweden', 'Czech Republic', 'Slovenia', 'Japan',
'Finland', 'Great Britain', 'Ukraine', 'Slovakia',
'Italy', 'Latvia', 'Australia', 'Croatia', 'Kazakhstan']
gold = [13, 11, 10, 9, 8, 8, 6, 5, 4, 4, 4, 3, 3, 2, 2, 2, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
silver = [11, 5, 10, 7, 7, 6, 3, 0, 8, 4, 1, 4, 3, 7, 4, 2, 4, 3, 1, 0, 0, 2, 2, 2, 1, 0]
bronze = [9, 10, 5, 12, 9, 5, 2, 1, 5, 7, 1, 2, 2, 6, 2, 4, 3, 1, 2, 1, 0, 6, 2, 1, 0, 1]
olympic_medal_counts_df = DataFrame({'country_name': Series(countries),
'gold' : Series(gold),
'silver' : Series(silver),
'bronze' : Series(bronze)})
return olympic_medal_counts_df
create_dataframe()
DataFrame (행/열) 데이터 조회
- 데이터프레임을 생성하고 전체 데이터 조회하기
- 각 컬럼별 컬럼명을 함께 할당 : 'column name' : [Series data 1, 2, 3 ...]
import pandas as pd
data = {'year': [2010, 2011, 2012, 2011, 2012, 2010, 2011, 2012],
'team': ['Bears', 'Bears', 'Bears', 'Packers', 'Packers', 'Lions', 'Lions', 'Lions'],
'wins': [11, 8, 10, 15, 11, 6, 10, 4],
'losses': [5, 8, 6, 1, 5, 10, 6, 12]}
football = pd.DataFrame(data)
football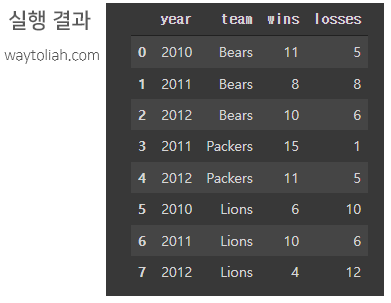
- 행방향 데이터(Index) 조회 : iloc, loc, column index, 단일 index 조건, 다중 조건 활용
# Row selection
print ("[1] iloc 활용 ")
print (football.iloc[[0]])
print ("\n[2] loc 활용")
print (football.loc[[0]])
print ("\n[3] column index 활용")
print (football[3:5])
print ("\n[4] 단일 index 조건 활용")
print (football[football.wins > 10])
print ("\n[5] 다중 조건 활용")
print (football[(football.wins > 10) & (football.team == "Packers")])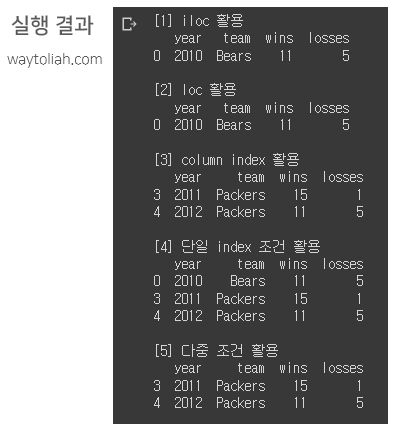
- 열방향 데이터, 단일 컬럼(Column) 조회 : 시리즈(Series) 반환
- data['컬럼명'] - data['column name']
- 데이터.컬럼명 - data.column_name
# Selecting a single column from the DataFrame will return a Series
football['year']
# shorthand for football['year']
print (football.year)
- 열방향 데이터, 여러 컬럼 조회 : 데이터프레임(DataFrame) 반환
# Selecting multiple columns from the DataFrame will return a DataFrame
football[['year', 'wins', 'losses']]
csv 파일 데이터를 읽어서 DataFrame 구조에 저장하기

- pd.read_csv( ) 를 활용하여 csv를 읽어 DataFrame으로 저장하기
import pandas as pd
# read data.csv to DataFrame
df = pd.read_csv('data.csv', header=0, index_col=0)
# Directory : Desktop case (바탕화면에 저장한 경우)
df = pd.read_csv(r'C:\Users\USER\Desktop\data.csv', header=0, index_col=0)
df
- 구글 colab에 csv 데이터를 업로드하고, DataFrame에 저장하기
from google.colab import files
files.upload()
df = pd.read_csv('data.csv', header=0, index_col=0)
df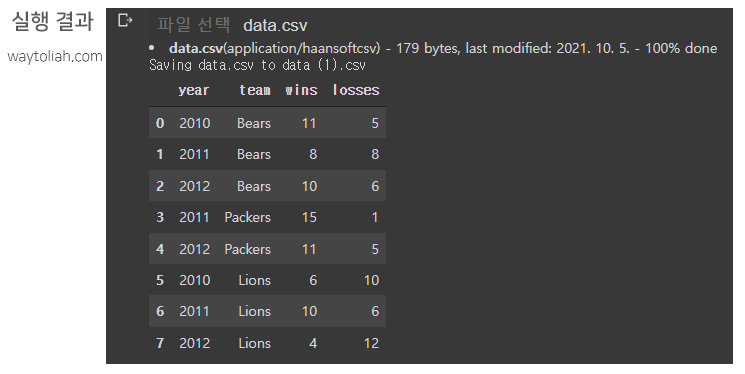
- pd.ead_csv( ) 주요 파라미터(Parameters)
- filepath (or) buffer : 파일경로/파일이름.csv 을 입력하여 파일을 불러오기
- sep (or) delimiter : 초기값은 comma(,) / 만일 분리 기준이 쉼표(,)로 분리되어 있지 않은 경우, 기준이 되는 값을 입력 (예: 슬라이스(/), Tab( ) 등 → sep="/" or delimiter=" " )
- header : 초기값은 0 / 컬럼명으로 사용할 행의 번호 입력
- names : 사용할 변수명 입력 / 파일에 변수명이 없다면 header를 None으로 설정
- index_col : 데이터의 인덱스로 사용할 컬럼 번호 입력
- skiprows : 첫 행을 기준으로 데이터를 얼마나 건너뛰고 읽을지 지정
- nrows : 파일을 읽어올 행의 수를 입력
- date_parser : 시계열 타입으로 변환할 변수 입력
DataFrame 을 csv로 저장하기
- .to_csv( ) 를 활용하여 DataFrame을 csv로 저장하기
data.to_csv('directory\data.csv', header=False, index=False)
'Biusiness Insight > Data Science' 카테고리의 다른 글
| [Python] 행렬의 연산(Matrix Multiplication) Numpy Dot 예제 (0) | 2021.10.22 |
|---|---|
| [Python] Lambda를 이용한 Vectorized Methods (0) | 2021.10.21 |
| Data Science 기본 역량 + Numpy, Pandas 활용 기초 (0) | 2021.10.03 |
| mAP, IOU란 + Object Detection 성능 평가 지표의 이해 및 예시 (1) | 2021.10.02 |
| 분석/참고용 데이터 소스 (1) | 2018.09.27 |



