반응형
Lambda를 이용한 Vectorized Methods (벡터화 방법 이해하기)
Lambda란?
- lambda 인수:식 (예: lambda x: x >= 1 )
- lambda 식을 사용하면 간단한 식의 경우, 인수에 람다식을 그대로 넣어 가독성이 좋아지고 불필요한 함수 정의 없이 코드를 깔끔하게 할 수 있음
- Lambda Expression : https://docs.python.org/2/tutorial/controlflow.html#lambda-expressions
데이터 프레임 생성하기
from pandas import DataFrame, Series
import numpy as np
d = {'one': Series([1,2,3], index=['a','b','c']),
'two': Series([1,2,3,4], index=['a','b','c','d'])}
df = DataFrame(d)
df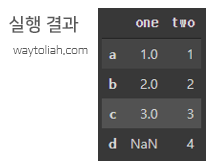
데이터프레임 각 열의 평균 구하기
# 각 열의 평균 구하기
df.apply(np.mean)
lambda 함수를 이용해 특정 행의 값이 1보다 크거나 같은지 확인
# lambda 함수를 이용해 각 행의 값이 1보다 크거나 같은지 연산
df['one'].map(lambda x: x>=1)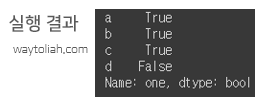
lambda를 이용해 각 행의 값이 1보다 크거나 같은지 모든 열을 확인
# lambda를 이용해 각 행의 값이 1보다 크거나 같은지, 모든 열을 확인
df.applymap(lambda x: x>=1)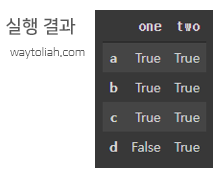
< 예제1 > 각 국가의 동메달 수 평균 구하기
from pandas import DataFrame, Series
import numpy
def avg_medal_count():
countries = ['Russian Fed.', 'Norway', 'Canada', 'United States',
'Netherlands', 'Germany', 'Switzerland', 'Belarus',
'Austria', 'France', 'Poland', 'China', 'Korea',
'Sweden', 'Czech Republic', 'Slovenia', 'Japan',
'Finland', 'Great Britain', 'Ukraine', 'Slovakia',
'Italy', 'Latvia', 'Australia', 'Croatia', 'Kazakhstan']
gold = [13, 11, 10, 9, 8, 8, 6, 5, 4, 4, 4, 3, 3, 2, 2, 2, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
silver = [11, 5, 10, 7, 7, 6, 3, 0, 8, 4, 1, 4, 3, 7, 4, 2, 4, 3, 1, 0, 0, 2, 2, 2, 1, 0]
bronze = [9, 10, 5, 12, 9, 5, 2, 1, 5, 7, 1, 2, 2, 6, 2, 4, 3, 1, 2, 1, 0, 6, 2, 1, 0, 1]
olympic_medal_counts = {'country_name':Series(countries),
'gold': Series(gold),
'silver': Series(silver),
'bronze': Series(bronze)}
df = DataFrame(olympic_medal_counts)
at_least_one_gold = df[df['gold'] > 0]
avg_bronze_at_least_one_gold = at_least_one_gold['bronze'].mean()
return avg_bronze_at_least_one_gold
print (avg_medal_count())실행결과 : 4.238095238095238
<예제 2 > 각 국가의 금메달, 은메달, 동메달 수 평균 구하기
import numpy
from pandas import DataFrame, Series
def avg_medal_count():
countries = ['Russian Fed.', 'Norway', 'Canada', 'United States',
'Netherlands', 'Germany', 'Switzerland', 'Belarus',
'Austria', 'France', 'Poland', 'China', 'Korea',
'Sweden', 'Czech Republic', 'Slovenia', 'Japan',
'Finland', 'Great Britain', 'Ukraine', 'Slovakia',
'Italy', 'Latvia', 'Australia', 'Croatia', 'Kazakhstan']
gold = [13, 11, 10, 9, 8, 8, 6, 5, 4, 4, 4, 3, 3, 2, 2, 2, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
silver = [11, 5, 10, 7, 7, 6, 3, 0, 8, 4, 1, 4, 3, 7, 4, 2, 4, 3, 1, 0, 0, 2, 2, 2, 1, 0]
bronze = [9, 10, 5, 12, 9, 5, 2, 1, 5, 7, 1, 2, 2, 6, 2, 4, 3, 1, 2, 1, 0, 6, 2, 1, 0, 1]
olympic_medal_counts = {'country_name':countries,
'gold': Series(gold),
'silver': Series(silver),
'bronze': Series(bronze)}
df = DataFrame(olympic_medal_counts)
avg_medal_cnt = df[['gold','silver','bronze']].apply(numpy.mean)
return avg_medal_cnt
print (avg_medal_count())실행결과 :
gold 3.807692
silver 3.730769
bronze 3.807692
dtype: float64
반응형
'Biusiness Insight > Data Science' 카테고리의 다른 글
| 비즈니스 분석 (Business Analytics) (1) | 2023.04.29 |
|---|---|
| [Python] 행렬의 연산(Matrix Multiplication) Numpy Dot 예제 (0) | 2021.10.22 |
| [Pandas] DataFrame 생성/조회, csv 불러오기/저장하기 (0) | 2021.10.05 |
| Data Science 기본 역량 + Numpy, Pandas 활용 기초 (0) | 2021.10.03 |
| mAP, IOU란 + Object Detection 성능 평가 지표의 이해 및 예시 (1) | 2021.10.02 |



